A Reflection on my 2022 Capstone Project
#webdev
#node
#javascript
#webscraper
Hi! For those of you who don't know me, I'm Cole. I develop video games and have participated in six game jams in the past three years, have had almost two years of web development experience between internships and contract jobs, had a brief stint as an actor in an embarrassingly bad Christmas movie, and now I'm completing my Bachelor of Computing Science at Thompson Rivers University.
For the capstone project of my degree, two peers and I were tasked to create a set of web scrapers that would retrieve product data from local stores by a start-up out of Kelowna. I was drawn to this project because while I had a lot of experience with web development, I had never worked professionally with Javascript or Node.js. I wanted to do a project that highlighted my existing skills in web development, while also developing new ones. To be honest, I also just didn't want to get stuck with a research project.
In this article, we're going to go over my main contribution to the project, the Lightspeed site structure implementation from the beginning. The decisions made, the challenges faced, the methods used, and the end result. I would also recommend you check out the work of my peers Justin Howson, and Adan Sierra Calderon, who did invaluable work on this project.
Initial Research
When we started this project, we were given a list of sites to research, eight of which were sites that used the Lightspeed site structure.
After doing a brief online course on web-scraping using Node.js, I started doing the laborious and boring task of putting together an HTML web scraper for required data points :( . During this time I was also doing research to find a more efficient (and less agonizing) way to get the data from the sites.
Eureka!
A couple weeks into the project, my teammate, Adan, pointed out that you could see API calls from websites using the Network tab in the Developer Tools. After testing this with the Lightspeed sites, I discovered that for each product being loaded, there was a call to a .ajax URL with the same name as that product.
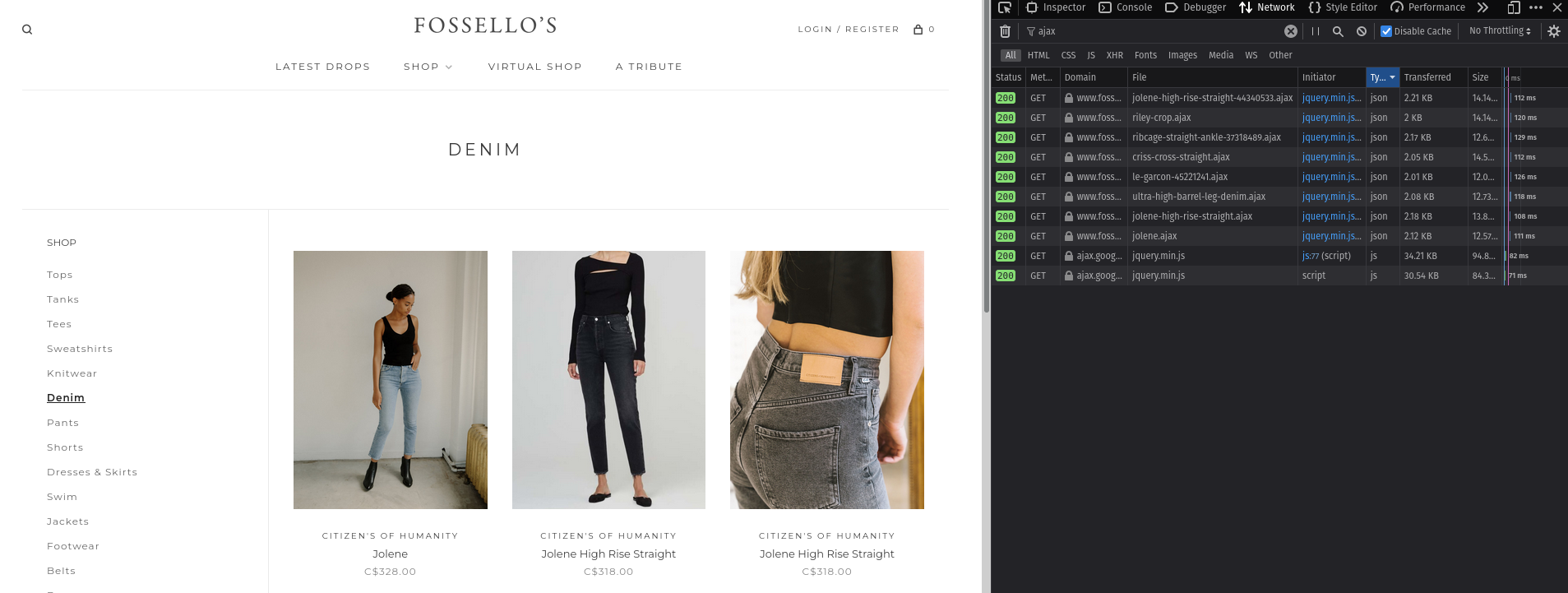
Lo and behold! Each URL contained a JSON object with all the information and more that we needed on each product including pricing, availability, images, variants, and more! This completely changed the project since now I could get more data reliably since I wasn't scraping data from HTML anymore (for the most part). From there, the gears started turning, and I started thinking about a structure that would best suit the client.
Priorities
Early in the project, our client had told us that speed was not a top priority for them. They would only be running these scrapers every once in a while to update their product library. With this in mind, I set a list of priorities for my scraper which included:
- - Scalability
- - Ease of Use
- - Readability
These came from the fact that we were working with a small, fast-moving start-up with limited resources and programmers. The scraper needed to be easily scalable with minimal effort. The last thing I wanted was for my code to be thrown away in a handful of months because it was too costly or time-consuming to maintain and expand.
The Structure
With my priorities in mind, I started building the structure of my project. I knew that I had three main things to do:
- - Get information needed for each website scraped like page URLs, and CSS selectors
- - Parse through the different pages, scraping all the product URLs and converting them to .ajax
- - Clean and output that data into a JSON array
I split these tasks up between three files respectively:
- - site_objects.js
- - product_url_scraper.js
- - index.js
site_objects.js contains only a list of objects, each one representing a single website. In each object there are 7 properties, 5 required, 2 optional, that represent the URLs for the different store pages on the website, and the required CSS selectors to get the product page URLs.
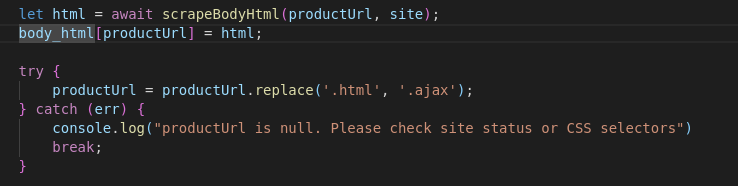
product_url_scraper.js contains functions that take the information from site_objects.js, goes through the product list on each store list, and scrapes the product URLs for each item. It then converts these .html URLs to .ajax and returns them all in an array. This is also where we get the body_html data point, but we'll get into that later.
Finally, index.js takes the URLs scraped in product_url_scraper.js and fetches the JSON data using node-fetch. This data is then cleaned to fit the data schema, added to a JSON array, and outputted in a .json file.
This structure makes it easier and much more intuitive to add websites to the scraper, and debug or expand in the future.
Challenges
Pagination
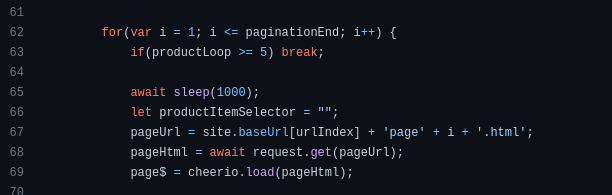
Handling pagination, the number of sub-pages in each store page, was one of the harder challenges of this project. I needed to accomplish a few things:
- - Find the amount of pages the scraper needs to parse through
- - Create it in a way that if more sub-pages are added to that page, a developer does not need to edit the value
- - Give an option for hard-coding the amount of pages parsed, while minimizing the need for it
Fortunately, I found that Lightspeed sites follow a similar convention for pagination.
base_url/page'x'.htmlwhere x is the index of the page.
This meant that all that was needed was the final page index and it could be looped through. To do this, I made a selector in site_objects.js called: paginationSelector, which gets the <li> element in the pagination list at the bottom of the page (as seen below).
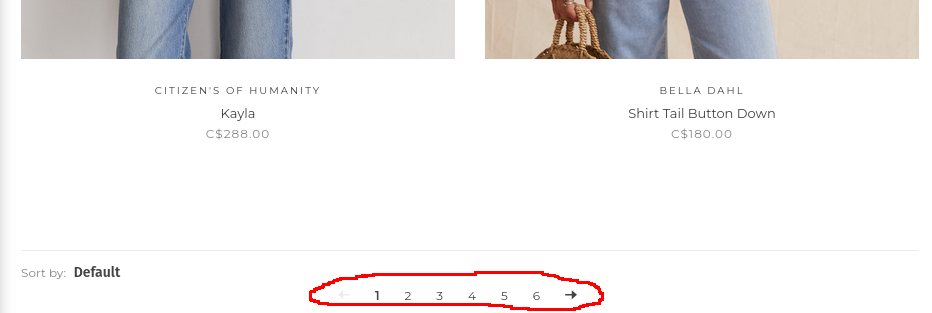
The scraper will then get the last element in that list, representing the last page, and use that as a condition for the loop.
This worked for the most part, but some sites had unconventional ways of handling pagination that this doesn't work on. One store in particular showed all the products on one page, but the user had to click a 'Show More' button to see them all. The site still used the URL structure of the others, but going past the pagination limit would cause the site to loop back on itself, so base_url/page5.html would show the same products as base_url/page1.html, leaving the scraper in an infinite loop and adding the same products multiple times to the results.
To account for this, I made a condition that checks if a URL has already been scraped, and if it has, it will not be added to the final results, and a value will be added to a productLoop variable. If that variable reaches a certain threshold, the loop will be broken, and the next page will be scraped.
Pagination was an issue that was worked on from the beginning of development all the way to the end, and highlighted my dedication to the priorities that I set out at the beginning of the project. The solution is understandable, flexible, and covers as many edge-cases as possible to minimize bug fixing for future developers.
body_html
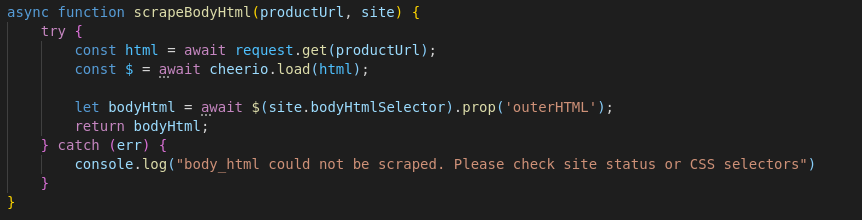
The body_html data point also provided a unique challenge during development. It stores the outerHTML property surrounding the description on each product page. Our client needed this data point so that they could have the description display in their app. Unlike the rest of the data points, body_html could not be taken from the JSON, and had to be scraped before the URL is converted from a .html to a .ajax extension.
To accomplish this, I added a new selector to site_objects.js called bodyHtmlSelector which gets the container surrounding the description on the product page.
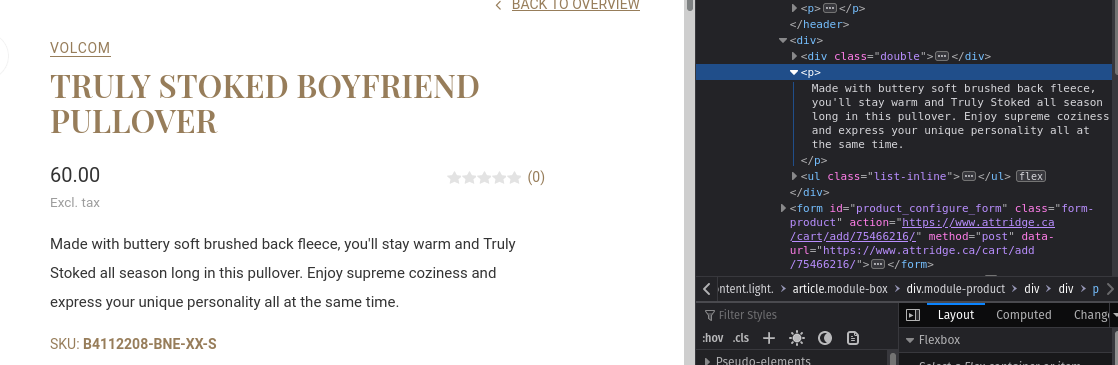
The scraper then uses JQuery to get the outerHTML attribute of this element and adds it to a body_html array, using that product page's URL as a unique key. The body_html data point is then added to each of the product's JSON object using that object's URL.
This challenge was an edge-case that forced me to think outside of my already established solution and problem-solve on the fly.
End Result
The Lightspeed scraper alone gets 1150 products in 12.5 minutes across 7 stores. However since it's so easy to add new sites to this scraper, it has the potential to get much more data as it's expanded on in the future. We had excellent feedback from our client and our professor.
Conclusion
This project allowed me to strengthen the skills I already had in web development, while also developing new ones. I was able to display my fore-thought about the future of a project, my problem-solving skills, my ability to learn new languages, tools, and techniques quickly, on a project that will provide value to our client for years to come.
You can go to this link to check out the project: ShopHopper 2022 Capstone Project